

Wheelwell combines a community of automotive enthusiasts with an extensive catalog of aftermarket parts. It was founded by self-described gear heads and tech geeks with a drive to create an exciting, customized shopping experience. Supported by its strong community, Wheelwell is the no.1 social marketplace for drivers, modders, and racers.
Retronyms Labs augmented and assisted the talented team at Wheelwell with several projects for both web and mobile. In addition to general app development, we deployed a strategic machine learning solution, and rolled out search — on an e-commerce platform where speed is king.
Vehicle ID Machine Learning
The Challenge
A core part of the Wheelwell community experience revolves around users sharing and showing off their modded rides. Could the experience of adding a car to your virtual garage be improved with artificial intelligence? We set out to speed up onboarding time by automating the creation of vehicle metadata. Our goal — a system that recognizes a car from a photo, and automatically fills in details like vehicle make, model, year, horsepower, torque, fitment, and so on.
Our Solution
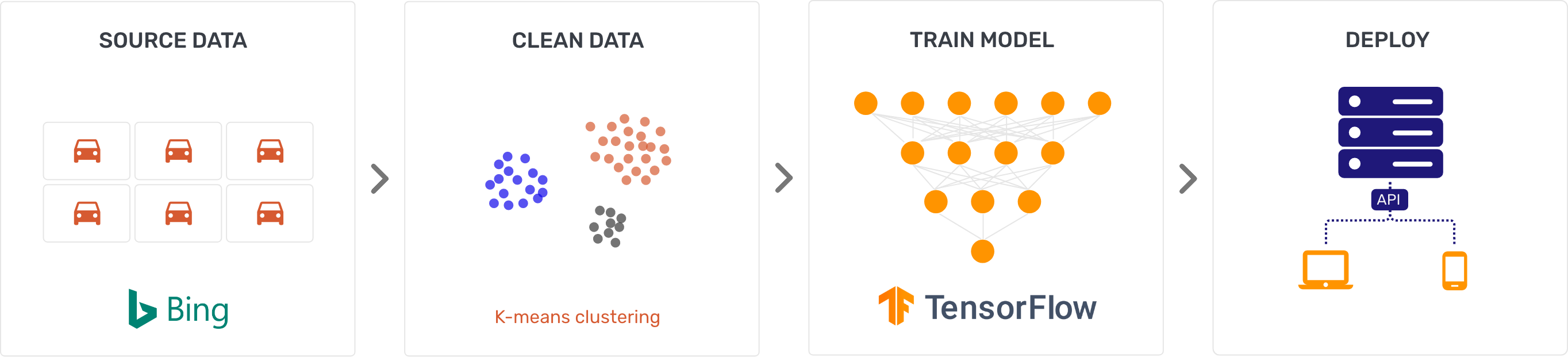
Neural networks have spawned a new era of algorithm-based intelligence and predictive analytics. The key to training them is a large dataset. Wheelwell identified about 20,000 distinct vehicle variations (year/make/model) that our application needed to be able to identify. It turns out this required around a million individually tagged images to effectively train the machine learning model.
To acquire this data, our first stop was Google. We quickly discovered that the Google Image Search API had been discontinued back in 2015, leaving Google Custom Search Engine (CSE) API as the next best alternative. You can imagine our dismay when we discovered that it was limited to 100 queries per day — at that rate, it would have taken us 27 years to collect the required dataset! Fortunately for us, there was BING. No, seriously — it turns out that Microsoft Azure provides a robust, usable, Bing Image Search API. Voila! We had the raw data we needed to run the machine learning model.
With Google, it would have taken us 27 years to collect the required dataset.
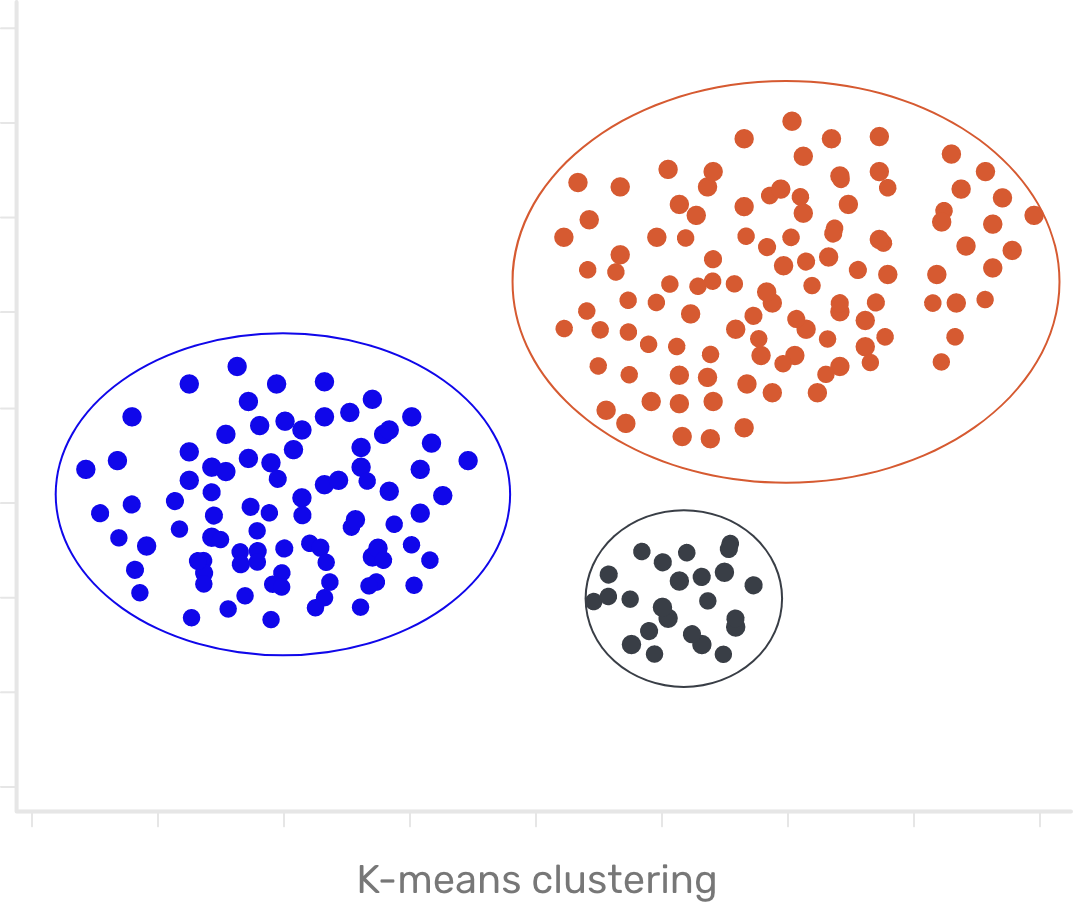
Then came the challenge of characterizing, categorizing, and cleaning up the data — a good job for K-means clustering. K-means belongs to a class of algorithms known as unsupervised machine learning algorithms. Unsupervised because they make inferences based solely on the input vectors and not on any labelled outcomes. Running a million images through K-means resulted in primary clusters of car exterior images, smaller clusters of interior images, and other scattered data. We discarded everything but the primary clusters. This served as our input.
Next we turned to TensorFlow — a popular machine learning platform — running on Amazon AWS instances to build and train our model. We initially started with a small set of images to ensure the training was running as expected. The data set was expanded when the results were in line with our expectations. We continued to test and retrain the model with more images until we achieved our target accuracy of ~95%. This process took several weeks. In the end, the model we built is able to successfully identify a vehicle from a single photograph 95 times out of 100. Can you tell the difference between a 2000 and a 2001 Ford Mustang? Vehicle ID can. From one photo. Of the bumper. It’s not smarter than you… just smarter at car photos.
Vehicle ID is not smarter than you… just smarter at car photos.
Indexing for Speed with ElasticSearch
The Challenge
A good search experience is central to any e-commerce platform. Getting it right involves not only showing the most relevant product results but also retrieving those results within a reasonable amount of time. ElasticSearch, when configured correctly, is capable of achieving both.
ElasticSearch was selected for the project due to its open source nature, scalable architecture, distributed model, and easy-access communication with a REST API. Although ElasticSearch is fairly easy to set up, it is hard to master without domain-specific knowledge. This is especially relevant when designing the appropriate indexing strategy, something fundamental to ensuring ElasticSearch works fast.
Technical Background
ElasticSearch relies on an index of the product database to search against. During indexing, ElasticSearch parses data based on the logic you define and stores it as internal documents in a structure similar to a JSON object. In turn, the data you start with becomes a set of correlating keys and values. Consider a car part attribute such as a model name. If we tell ElasticSearch to consider it as a keyword, there will be minimal processing of that data. In contrast, if we tell it to consider it as general text data, it’ll do a lot more language-specific parsing. Keyword search results are a lot stricter in that an exact match is necessary to show the relevant result. However, in the case of general text data, the extra parsing helps account for non-exact matches. Therefore, the right index setup can make or break the search experience.
Wheelwell’s marketplace runs on a complex database with tens of millions of products. Each product has multiple types of data including name, part ID, SKU, car compatibility, color, and more. Moreover, each product also has a layer of metadata attached to it that is relevant for proper sorting and filtering. When querying for a product, all of this information has to be accounted for.

Our Solution
We started with a list of sample search queries and the results we were expected to get based on a variety of factors. This served as a benchmark to test against to ensure our indexing strategy was on the right track.
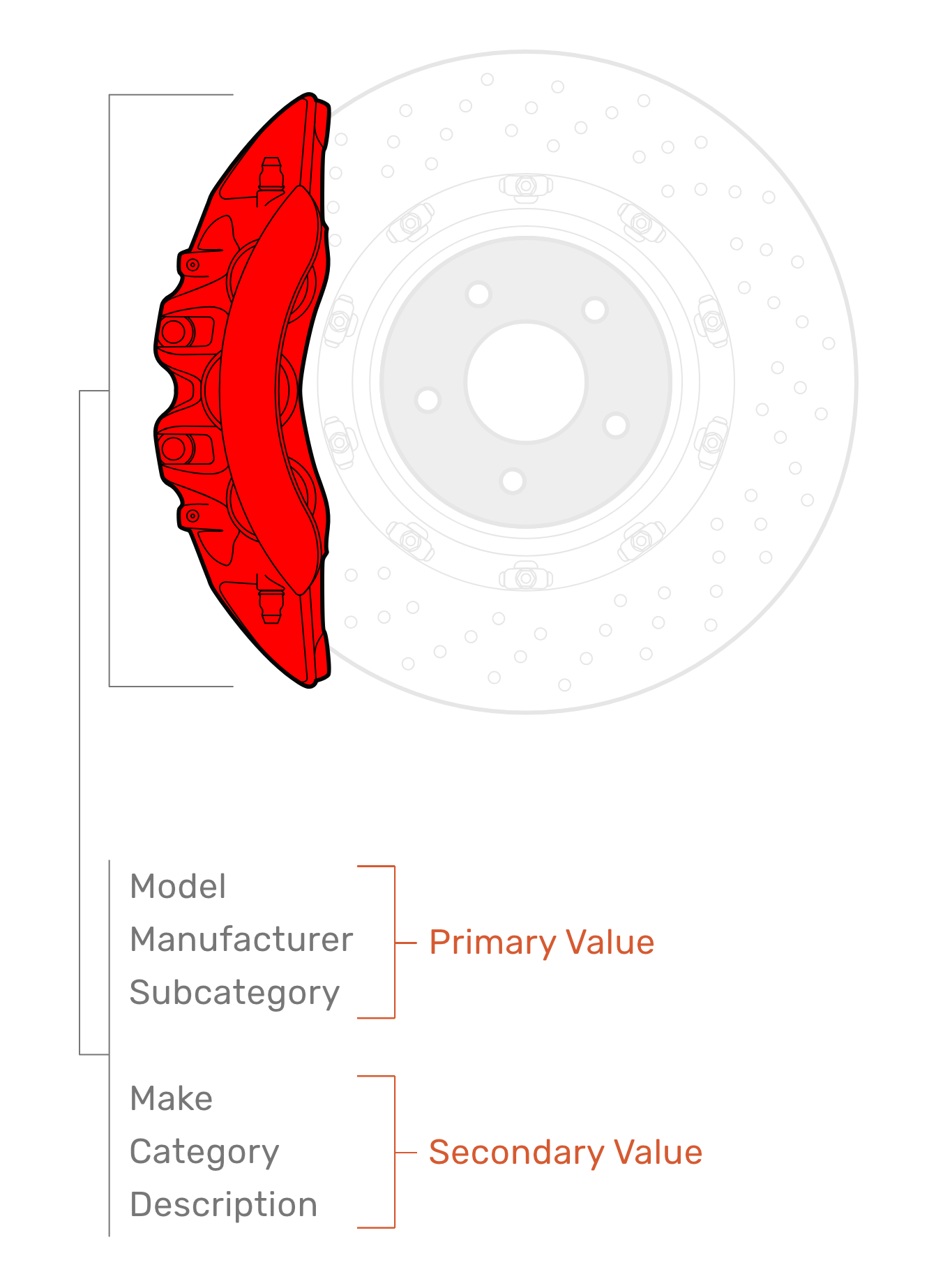
Several rounds of index setup optimizations led us to a big breakthrough — using a key domain and business related processing optimization centered around full text search use cases. We identified six main attributes-of-interest for each car part. Out of those, three attributes had primary value and three had secondary value. Instead of considering these as individual fields that required complex queries, we lumped the three primary value attributes into one full text field and the three secondary value attributes into another full text field. While both fields got equal treatment at index time, they were given different weights during search time. This one optimization resulted in a massive improvement. Relevance increased, and we shaved 1500 milliseconds off search time — a 75% increase.
About Retronyms Labs
Retronyms Labs combines design, engineering, and strategy to create integrated-technology solutions. Your business is more than an app. It connects people to real experiences, enables meaningful communication, and engagement with the real world. We work across multiple stacks of software, hardware, and design to bring those experiences to life.